【IT168 评测】早在去年,英特尔推出了面向桌面级应用的Sandy Bridge微架构处理器——第二代智能英特尔酷睿博锐处理器,也就是我们见到的32nm酷睿i3\i5\i7。作为今年的英特尔Tock之年,虽然在工艺制程上依然使用的是32nm工艺,与去年相同;但是相比之前将CPU与GPU分别封装不同的是,Sandy Bridge使用的是统一的封装方式,从而在性能及功耗多方面达到了新的高度,更符合时下节能减排、低碳生活的理念。

Intel发布Sandy Bridge微架构32nm处理器
每当提到Sandy Bridge的技术特点——环形总线、AVX指令集、Turbo Boost2等内容都是众多报道中频繁出现的内容。究竟这些技术为我们带来了什么?它们的存在会有哪些好处?对于商用电脑来说,性能与功耗之间当如何寻找平衡点?下面的文章中,我们将为大家详细解答以上的问题。
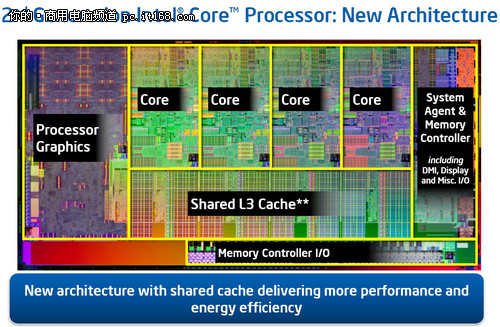
正如刚才提到的,第二代智能英特尔酷睿博锐处理器给我们带来的一个印象就是采用了环形总线架构,这也是Intel在继服务器行业中的Nehalem和Westmere之后继续使用环形总线的架构。
Sandy Bridge核外架构图
Sandy Bridge处理器使用了新的环形总线设计。事实上从之前的至强Nehalem开始,英特尔就转向了融合核心的理念。在Nehalem当中,英特尔将内存控制器融入其中,而在接下来的Westmere当中,GPU也作为融入的对象而出现(只是那时候的GPU还仅仅使用的是45nm工艺)。在之前的8核心Nehalem-EX上,我们就看到了环形总线的身影,不过当时的产品在性能和功耗上并没有表现出明显的优势。
本次Sandy Bridge使用的是重新设计的核外结构,全新的Ring Bus环形总线更能够较好的展示出Sandy Bridge的真实性能。通过上图大家可以看到,Ring Bus环形总线连接各个CPU核心、LLC缓存(L3缓存)、融合进去的GPU以及System Agent(系统北桥)等部分。
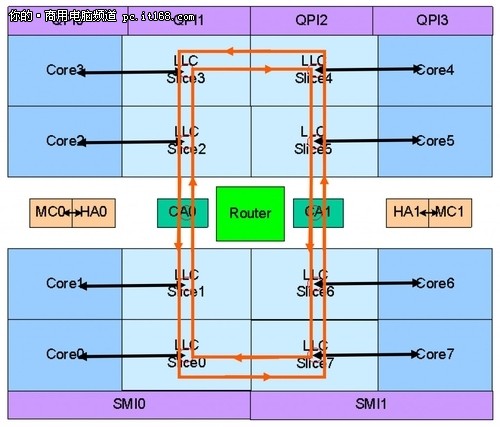
这个图片或许可以更好的说明问题。新的Ring Bus环形总线由四条独立的环组成,分别是数据环Data Ring、请求环Request Ring、响应环Acknowledge Ring和侦听环Snoop Ring。借助于环形总线,CPU与GPU可以共享LLC缓存,将大幅度提升GPU性能。
在这个环形总线上,分布着多个Ring Stop,也就是俗称的“站台”。这个“站台”在每个CPU/LLC块上具有两个连接点,而之前使用环形总线的产品,也就是Nehalem-EX环在每个CPU/LLC块上只有一个连接点。
环形总线的存在,可以大大减少核心访问三级缓存的周期。在以往的产品中,多个核心共享一个三级缓存,需要访问的话必须先经过流水线发送请求,在进行优先级排序之后才能进行。新的环形总线将三级缓存分割成了若干部分,借助于每个站台,核心可以快速的访问LLC。LLC小容量缓存的延迟优势与核心频率一致性在这里也就体现了出来,这就使得Sandy Bridge的周期相比以往产品有所缩减,从原来的35-40个缩减到了26-31个。同时,由于每个核心与LLC之间可以提供若干带宽,使得Sandy Bridge的整体带宽也提升了4倍。
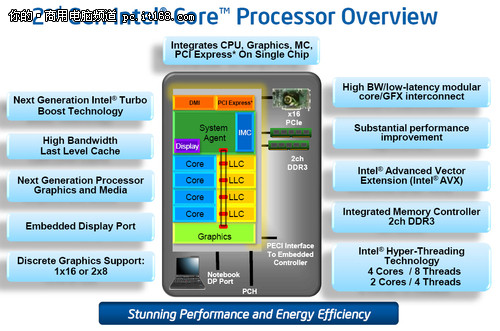
在Sandy Bridge架构中,英特尔使用了一个全新的概念——System Agent(系统助手)。事实上,System Agent也就是我们之前所说的核外架构,只是英特尔本次给予了其全新的命名,而在以往的名称中,我们亲切的称之为系统北桥。
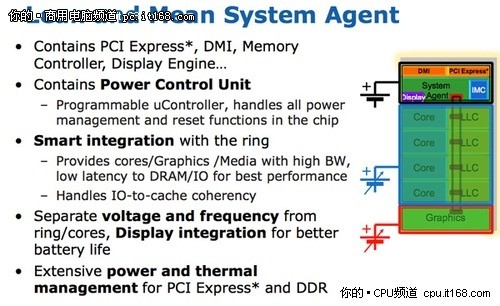
系统助手
System Agent包含了比以往产品更为丰富的功能,包括整合内存控制器、支持16条PCIE2.0通道的PCIE控制器、图形处理器(GPU)、电源控制单元(PCU)以及DMI总线的IO接口。
PCI-E控制器,可提供16条PCI-E 2.0信道,支持单条PCI-E x16或者两条PCI-E x8插槽;
重新设计的双通道DDR3内存控制器,内存延迟也恢复了正常水平(Westmere将内存控制器移出CPU、放到了GPU上);
此外还有DMI总线接口、显示引擎、电源控制单元(PCU)。
系统助手的频率要低于其他部分,有自己独立的电源层。
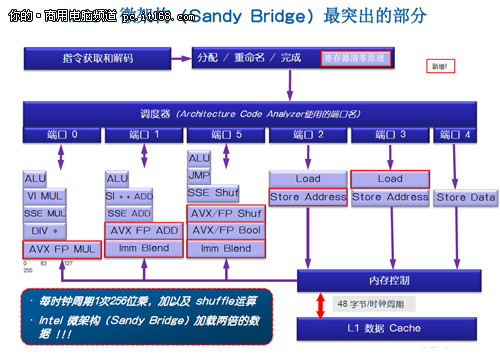
在Sandy Bridge架构中,最大的改进要算是增加了全新的AVX指令集——Advanced Vector Extensions,高级矢量扩展。这个指令集的增加是X86处理器中的重要内容,不仅仅是提供了更为良好的性能,同时也是对现有指令集的整合与优化。
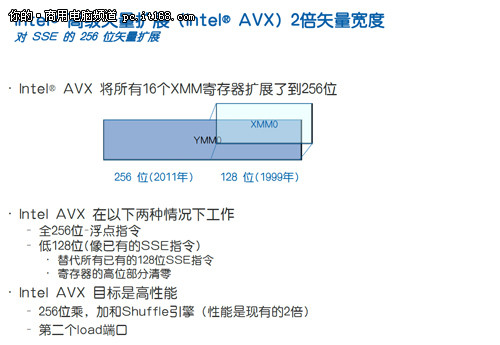
介绍AVX指令集之前,先要引入一个向量的概念。所谓向量,就是多个标量的组合,通常意味着SIMD(单指令多数据),就是一个指令同时对多个数据进行处理,达到很大的吞吐量。早在1996年,英特尔就在X86架构上应用了MMX(多媒体扩展)指令集,那时候还仅仅是64位向量。到了1999年,SSE(流式SIMD扩展)指令集出现了,这时候的向量提升到了128位。

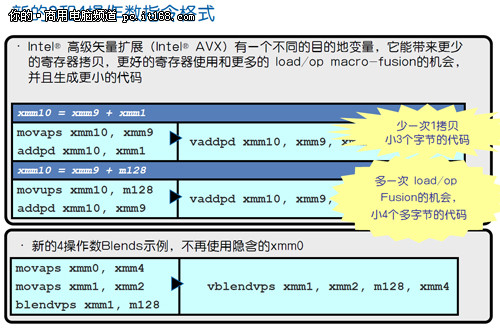
如今,Sandy Bridge的AVX将向量化宽度扩展到了256位,原有的16个128位XMM寄存器扩充为256位的YMM寄存器,可以同时处理8个单精度浮点数和4个双精度浮点数。换句话说,Sandy Bridge的浮点吞吐能力可以达到前代的两倍。不过现在,AVX的256位向量还仅仅能够支持浮点运算。不过AVX的特别之处在于,它可以应用128位的SIMD整数和SIMD浮点路径。
既然我们一直在讨论Sandy Bridge核心,那么不谈到其特色的整合GPU显然是不合适的,虽然对于服务器的应用来说多媒体性能的确是无足轻重。其实我们在文章最初就提到过,作为Tick-Tock时钟式的重要内容,其实从Westmere 32nm处理器开始,Intel就在处理器中整合了GPU,不过仅仅是将二者封装在一个Die上。因为45nm的GPU与32nm的CPU在制程上不一致,最重要的是关键的内存控制器被放在了45nm的GPU当中,造成了32nm Westmere性能并没有想象的那么出色。而在Tock中,Sandy Bridge的出现解决了这一问题,特别是将GPU整合在了环形总线之内,实现了二者真正的融合。
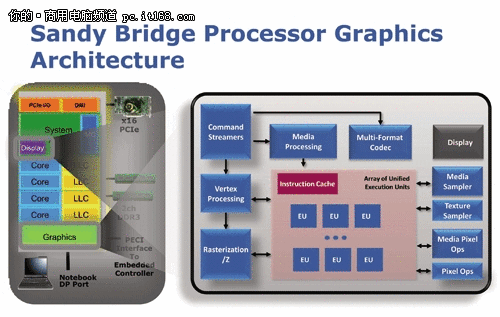
SandyBridge GPU有自己的电源岛和时钟域,也支持Turbo Boost技术,可以独立加速或降频,并共享三级缓存。显卡驱动会控制访问三级缓存的权限,甚至可以限制GPU使用多少缓存。将图形数据放在缓存里就不用绕道去遥远而“缓慢”的内存了,这对提升性能、降低功耗都大有裨益。
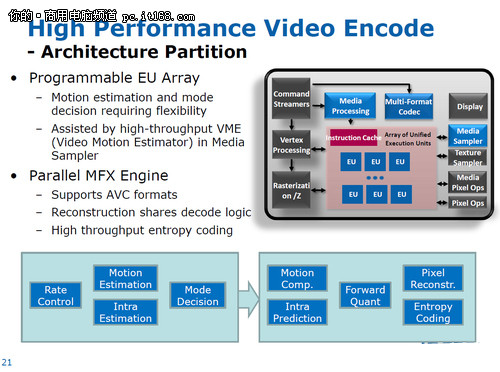
可编程着色硬件被称为EU,包含着色器、核心、执行单元等,可以从多个线程双发射时取指令。内部ISA映射和绝大多数DX10.1 API指令一一对应,架构很像CISC,结果就是有效扩大了EU的宽度,IPC也显著提升。抽象数学运算由EU内的硬件负责,性能得以同步提高。
英特尔此前的图形架构中,寄存器文件都是即时重新分配的。如果一个线程需要的寄存器较少,剩余寄存器就会分配给其他线程。这样虽能节省核心面积,但也会限制性能,很多时候线程可能会面临没有寄存器可用的尴尬。在芯片组集成时代,每个线程平均64个寄存器,Westmere HD Graphics提高到平均80个,SandyBridge则每个线程固定为120个。
刚刚,我们分析过了第二代智能英特尔酷睿博锐处理器,也就是基于Sandy Bridge微架构处理器的相关信息。从规格来看,32nm已经是目前处理器制造工艺的最高水平,而这样的工艺也决定了处理器本身并不会有太高的发热量,能耗非常低。但仅仅凭借制程工艺的革新还是不够的,硬件与软件的双重努力才决定了处理器本身的低碳环保。下面,我们就来看看英特尔为节能减排做了哪些工作。
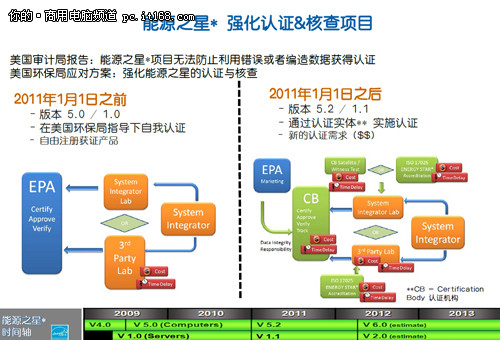
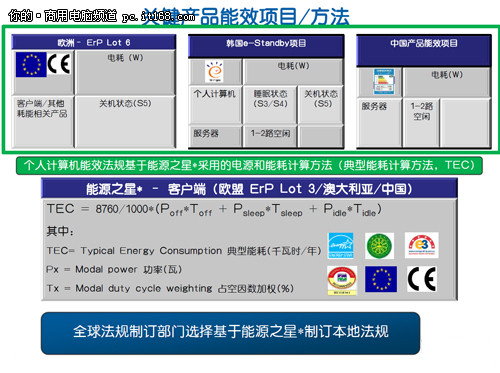
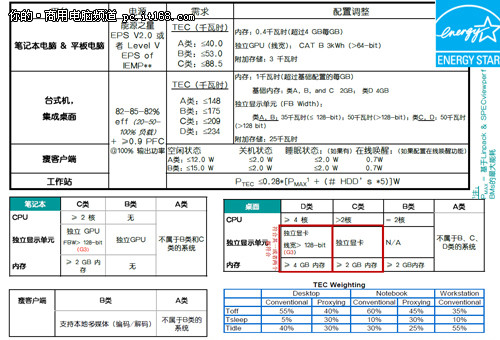
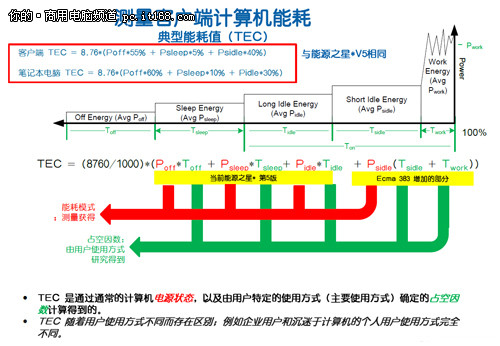
对于商用电脑来说,功耗与性能更是用户关注的方面。商用电脑由于需要长时间使用,更注重低碳与节能。有了最新的能源之星标准要求,第二代智能英特尔酷睿博锐处理器更值得企业用户信赖。应该说,从最初的研发技术到最终的软件配置,英特尔都秉承了节能减排的要求,这一举措也必将得到行业的支持。

